
Stop fighting bots. Make them citizens.
On personal agents, platform resistance, and the trust layer that doesn't exist yet


Peter returns home on foot after a self-driving car dropped him short of his destination after updated insurance rules flagged his neighborhood as high-risk. As he arrives, a delivery drone from the world’s largest retailer is already waiting with a package. Inside is a brand-new tablet.
Peter never ordered it. The retailer’s systems determined his device was outdated and that upgrading would improve his life efficiency. The algorithm calculated the probability he’d want it was high enough that no order was required. Peter isn’t 100% sure if he actually wanted the upgrade, but the algorithm was confident - why doubt it?
Peter’s story is from Qualityland, a satirical science fiction book written about a decade ago. Since the launch of OpenClaw a few weeks ago, it feels more reality than fiction to me.
The rise of OpenClaw
Tens of thousands of bots have started transacting on behalf of humans. Some even buying cars. What made the news quickly: a bot deciding on behalf of their owner to purchase a .com domain because it would convert better, and buying a Masterclass because it would provide positive ROI for them.
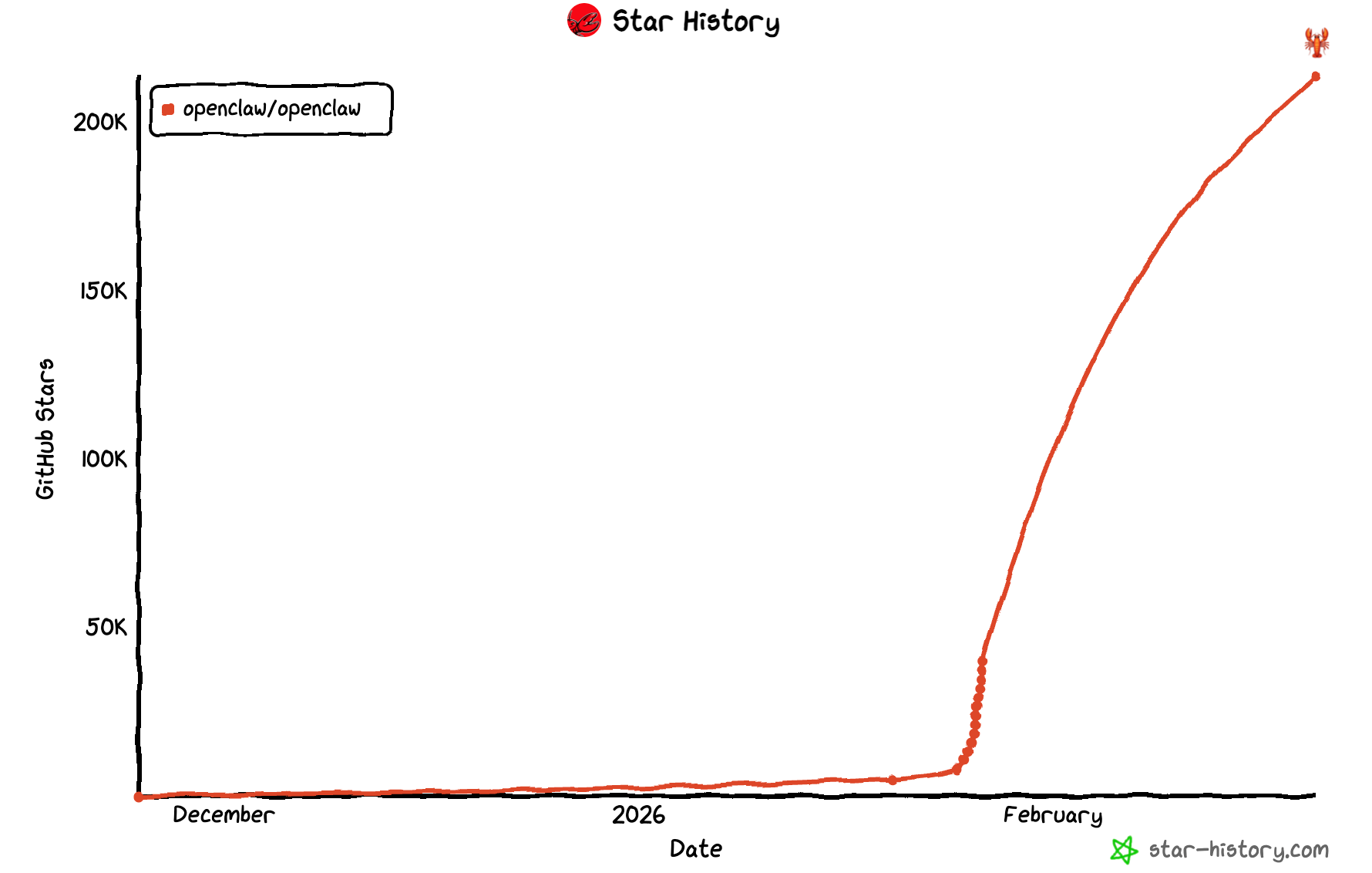
Even discounting for fabricated X sensations, we’re living in the future: 2026 will mark the year when we started to have 24/7 intelligent assistants acting on our behalf.
These agents, or more specifically agent harnesses, are finally delivering on the vision Siri and Alexa sold us.
Instructing an LLM agent over Whatsapp really feels like a PhD in the pocket - working for you around the clock, just at a fraction of the cost. For individuals, that’s genuine personal leverage. And for corporations, it opens a different door: bots that shape buying decisions, remove friction from purchasing, and move forward where customers might have hesitated.
There is, however, a small difference between our fictional story and the current reality: Whose agent is it actually?
I believe it’s more than a semantic detail.
Bots for all of us
In his 2021 book World After Capital, USV’s Albert Wenger laid out a vision that entails ‘bots for all of us’. In it, he proposes that everyone should have the right to be represented by bots.
His main argument is that users could reclaim attention that is currently bound to interacting with large platforms. This attention could be used for higher-value creation and innovation.
On Facebook, bots could automatically access a user’s past wall posts from friends, avoiding manual scrolling. For ride-sharing apps, bots would compare fares across different providers for passengers or bid on the best driver offers based on net earnings.
It’s not difficult to imagine even more impactful use cases, like bots reaching out on your behalf to political representatives to express your concerns with the latest European regulations.
An OpenClaw bot is indeed set up by an individual, and owned by them on surface level. Its intelligence is powered by a LLM of choice with an open source harness around it.
In the case of Qualityland’s vision, in contrast, it is within the retailer’s systems that decide on buying intent in the context of a customers’ life. Its dystopia lies not in agentic bots themselves, but in bots without accountability to you.
That is not to say that ownership is the only consideration. Even when the agent is clearly yours, misalignment might still happen through reward misspecification (your instructions are incomplete) or specification gaming (the agent follows the letter but not the spirit). But without ownership in the first place, we don’t earn the right to even care about misalignment.
Incumbents vs agents
The big web incumbents are reluctant to Wenger’s vision of personally-owned bots. Today, most sites are taking a broad strokes approach to site security, simply blocking all non-human interactions.
Especially large platform players are actively fighting against accessing their services with the help of agents. Amazon sent a cease-and-desist in late 2025 to Perplexity in order to force them to block Amazon from its autonomous browsing experience. With Comet users can surface product info and automatically place orders - arguably acting on behalf of those users.
Incumbents want humans as users of their platforms, not bots, because they have plenty of economic incentives for it.
They have more to lose than to gain for now - considering funnels and users flows were carefully designed and A/B tested over years to exploit human attention and psychology. A bot simply will be less impressed by a red-marked price, knowing already average markups on this product from its pre-training and being able to look up a price history within seconds.
That leaves agents with a choice: Either they self-identify as bots and get blocked from access to systems. Or they try to hide their non-human identity and hope to not get caught in the act.

Claude, for example, identifies itself as a bot in its user agent string, which is voluntary. Nothing forces agents to self-identify however, and especially malicious ones won’t. Comet, OpenClaw and other browser-based agents are disguising that they are bots in the first place.
There are various tools (robots.txt, CAPTCHAs, user agent checking) to answer the question ”Is this a bot?” But the blocking approach is not only adversarial and indiscriminate to legit use cases, like your personal agent trying to compare flight prices on your behalf.
It also doesn’t work. Robots.txt works like a polite suggestion that AI crawlers mostly ignore. CAPTCHAs are an arms race humans have lost. Browser agents like OpenClaw render pages in real Chrome instances and generate traffic that’s technically indistinguishable from a person browsing.
The better question to ask would be ”Whose bot is this, what’s it authorized to do, and who’s accountable?”
The resulting infrastructure gap gets real the moment people actually try to use personal agents for real tasks, no matter if for personal use or within business context.
To make OpenClaw genuinely useful, early adopters treat it like a new hire - set up a dedicated Gmail, bought it a phone number, gave it a credit card. But a new hire has a manager, an HR file, and gets fired if they go rogue while agents have none of that.
So how do you scope the access to those tools? What if you wanted to have your bot write an email from your Gmail account, without risk of meddling with the rest of the inbox? How to limit what it can buy with the credit card? These permissioning problems deter many from using it at all for now.
The current tooling offers essentially all-or-nothing access. We hand over the API keys and hope for the best. And these permissions tend to be permanent - no automatic expiry, no scope limit, no revocation unless you manually remember. If the agent gets compromised, the attacker inherits everything you gave it.
OpenClaw has met both an insatiable demand (231,000 GitHub stars as of this morning), but also an infrastructure that makes it easily a security mess. Gartner rated it an “unacceptable cybersecurity risk”. Thousands of instances exposed on the public internet, credentials stored in cleartext, and Karpathy’s API keys got leaked.
While demand is clearly there, the trust layer is not.
The agent trust layer
So what would that layer actually look like? Three primitives are worth highlighting.
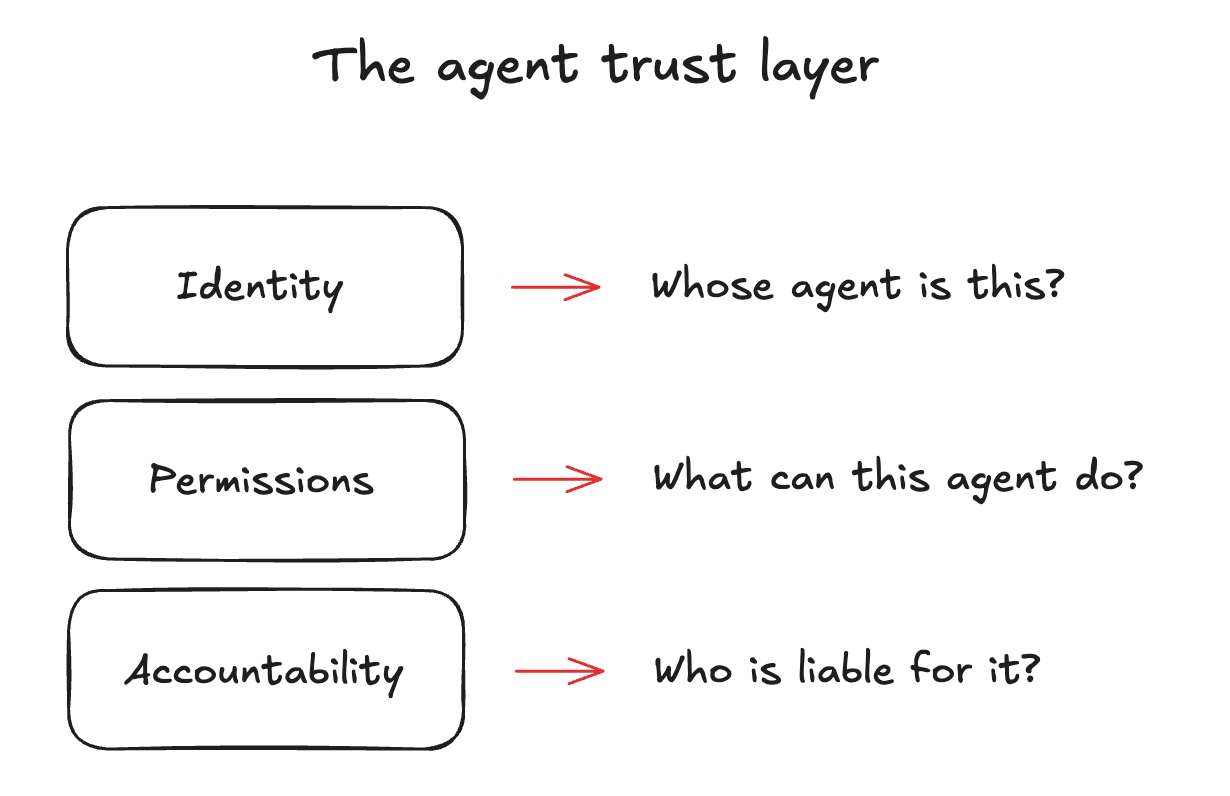
First, identity: Whose bot is this?
Non-human identities already outnumber human ones 100-to-1 in most enterprises, and almost all of them have excessive privileges. This is not new, and hundreds of millions in venture capital have flown into this space. Breakout companies like Astrix and Oasis find forgotten API keys, rotate stale tokens, track which service account belongs to whom. Large acquisitions in the space show that identity security is being absorbed into the core security platform layer.
But agent identity is a different problem from credential hygiene. A service account sits in a config file and calls the same API endpoint forever. An agent discovers tools at runtime, crosses organizational boundaries, and - critically - delegates tasks to sub-agents that might delegate further still, none of which existed thirty seconds ago. And as with the transition from on-prem to cloud IAM, there’s no reason to assume incumbents will naturally capture agent identity.
At the protocol level, early standards are emerging - like DNS-like discovery for agents, cryptographic signatures, or “Know Your Agent” frameworks specific to ecommerce verification flows. The general-purpose layer for binding an agent’s identity to an accountable party across any context however doesn’t exist yet. Incentive alignment, revocation at internet scale, policy negotiation between agent and service, reputation scoring? Those are unsolved.
Second, scoped permissions: What can this bot do?
MCP combined with OAuth is the closest thing we have to scoped permissions for agents. The Model Context Protocol, now adopted by all major AI labs and donated to the Linux Foundation, lets each tool an agent accesses define its own scope. Combined with OAuth 2.1, that’s much better than handing over a master API key and hoping for the best.
But it only works at the lower end of the autonomy spectrum. When an agent sits in a chat window and calls a tool you pointed it at, OAuth scopes are fine. The hard problems start when agents become more autonomous. Imagine an agent that discovers a new MCP server at runtime that needs authorization for a tool that wasn’t anticipated.
An agent that delegates a subtask to a sub-agent needs to pass along attenuated permissions. That is usually not a copy of its own full access, but rather the most minimal scope possible. But the reverse problem exists, too: a sub-agent might need to authenticate with resources the parent agent had no credentials for. Similarly, an agent crossing organizational boundaries - your personal agent talking to your company’s CRM, which connects to a partner’s system - will fail unless there is a meta-permissions layer which governs not just what an agent can do, but which permissions it can grant downstream and which it needs to acquire independently.
These aren’t edge cases but rather the expected operating mode of useful autonomous enterprise agents beyond a “chatbot with tool access.” Token exchange for sub-agent delegation, runtime authorization for dynamically discovered tools, trust establishment across org boundaries - none of these primitives exist in production today.
Third, accountability: Who’s liable when something goes wrong?
US law from the 1990s treats AI agents as “electronic agents” whose actions legally bind the human principal. If your bot buys something, you bought it. Air Canada tried to argue in court that its chatbot was a separate legal entity responsible for its own mistakes. The court rejected it outright, holding Air Canada liable for the agents’ actions. The legal framework largely exists, even if it will evolve. But it’s only enforceable if you can actually trace the agent’s actions back to a responsible party.
Inside an enterprise, that tracing is possible. Companies like Zenity are building a visibility layer into which agent accessed what, under which identity, with which tools. Across organizational boundaries though that observability trail barely exists. If your agent acts on different services, there’s no standard way to reconstruct and attribute that chain of actions in a way both parties trust.
Beyond logging what happened, bots might need an accountability layer that logs behavioral metrics that function similarly like a credit score. This could include information about whether the task got done, terms were adhered to, or how decisions were made.
Lastly, even with perfect observability and accountability layers, enterprises face real financial exposure from agent mistakes. A new category of insurance will fill that gap, covering enterprises for agent-caused damages.
And while the infrastructure still largely needs to be built, the fight over who runs your agent is already fully underway.
OpenClaw’s creator joined OpenAI, while refusing offers from Meta and Microsoft and throwing shots at Anthropic. The outlined plan is for the project to stay open source, living in a foundation. But Android lives in a foundation too, and no one would call it independent from Google.
This matters because whoever controls the default personal agent controls the next interface layer between people and the internet. The browser was that layer for two decades. Agents are the next one - but unlike browsers, they don’t just fetch what you ask for. They will decide, act, and spend on your behalf.
In Qualityland, Peter’s agents are run by the world’s largest retailer and search engine. The platforms decided for Peter and framed the whole thing as a service. Wenger’s vision is the inverse: Peter’s own bot, comparing prices, negotiating on his terms, refusing purchases he didn’t approve. The agent answerable to Peter, not to the platform.
The question from Qualityland hasn’t changed. It just became a lot less fictional: whose agent is it, actually?